Experiment 1.5: Smooth curriculum and anchoring
This experiment combines the insights and tools from our previous work:
- 3D Bottleneck & Curriculum: Like Experiment 1.3, we use a low-dimensional latent space and a curriculum to encourage the model to learn hue first.
- Smooth Transitions: We replace the abrupt phase changes of Ex 1.3 with the smooth parameter transitions developed in Experiment 1.4, using the
SmoothPropmechanism driven by a dopesheet. - Anchoring: We introduce an "anchor" regularization term, also controlled via the dopesheet, to fix the positions of key colors (primaries/secondaries) after the initial phase, preventing later phases from disrupting the learned hue structure.
This time we use four dimensions: two for hue, and one each for value and saturation. This is actually more than is strictly needed: consider that both HSV and RGB only use three dimensions! But they use a dense cube, whereas our latent space will be the surface of a hypersphere.
We hope to achieve a stable, well-structured latent space where hue forms a planar color wheel, while value and saturation extend into the dimension remaining dimensions. We expect this approach to be less sensitive to the initial conditions and exact timing and weighting of curriculum phases compared to the discrete steps in Ex 1.3.
from __future__ import annotations
import logging
from utils.logging import SimpleLoggingConfig
logging_config = SimpleLoggingConfig().info('notebook', 'utils', 'mini', 'ex_color')
logging_config.apply()
# This is the logger for this notebook
log = logging.getLogger('notebook')
import torch
import torch.nn as nn
E = 4
class ColorMLP(nn.Module):
def __init__(self, normalize_bottleneck=False):
super().__init__()
# RGB input (3D) → hidden layer → bottleneck → hidden layer → RGB output
self.encoder = nn.Sequential(
nn.Linear(3, 16),
nn.GELU(),
# nn.Linear(16, 16),
# nn.GELU(),
nn.Linear(16, E), # Our critical bottleneck!
)
self.decoder = nn.Sequential(
nn.Linear(E, 16),
nn.GELU(),
# nn.Linear(16, 16),
# nn.GELU(),
nn.Linear(16, 3),
nn.Sigmoid(), # Keep RGB values in [0,1]
)
self.normalize = normalize_bottleneck
def forward(self, x: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
# Get our bottleneck representation
bottleneck = self.encoder(x)
# Optionally normalize to unit vectors (like nGPT)
if self.normalize:
norm = torch.norm(bottleneck, dim=1, keepdim=True)
bottleneck = bottleneck / (norm + 1e-8) # Avoid division by zero
# Decode back to RGB
output = self.decoder(bottleneck)
return output, bottleneck
Training machinery with timeline and events
The train_color_model function orchestrates the training process based on a Timeline derived from the dopesheet. It handles:
- Iterating through training steps.
- Fetching the correct data loader for the current phase.
- Updating hyperparameters (like learning rate and loss weights) smoothly based on the timeline state.
- Calculating the combined loss from reconstruction and various regularizers.
- Executing the optimizer step.
- Emitting events at different points (phase start/end, pre-step, actions like 'anchor', step metrics) to trigger callbacks like plotting, recording, or updating loss terms.
from dataclasses import dataclass
from typing import Protocol, runtime_checkable
from torch import Tensor
import torch.optim as optim
from mini.temporal.model import TStep
@dataclass
class InferenceResult:
outputs: Tensor
latents: Tensor
def detach(self):
return InferenceResult(self.outputs.detach(), self.latents.detach())
def clone(self):
return InferenceResult(self.outputs.clone(), self.latents.clone())
def cpu(self):
return InferenceResult(self.outputs.cpu(), self.latents.cpu())
@runtime_checkable
class LossCriterion(Protocol):
def __call__(self, data: Tensor, res: InferenceResult) -> Tensor: ...
@runtime_checkable
class SpecialLossCriterion(LossCriterion, Protocol):
def forward(self, model: ColorMLP, data: Tensor) -> InferenceResult | None: ...
@dataclass(eq=False, frozen=True)
class Event:
name: str
step: int
model: ColorMLP
timeline_state: TStep
optimizer: optim.Optimizer
@dataclass(eq=False, frozen=True)
class PhaseEndEvent(Event):
validation_data: Tensor
inference_result: InferenceResult
@dataclass(eq=False, frozen=True)
class StepMetricsEvent(Event):
"""Event carrying metrics calculated during a training step."""
total_loss: float
losses: dict[str, float]
class EventHandler[T](Protocol):
def __call__(self, event: T) -> None: ...
class EventBinding[T]:
"""A class to bind events to handlers."""
def __init__(self, event_name: str):
self.event_name = event_name
self.handlers: list[tuple[str, EventHandler[T]]] = []
def add_handler(self, event_name: str, handler: EventHandler[T]) -> None:
self.handlers.append((event_name, handler))
def emit(self, event_name: str, event: T) -> None:
for name, handler in self.handlers:
if name == event_name:
handler(event)
class EventHandlers:
"""A simple event system to allow for custom callbacks."""
phase_start: EventBinding[Event]
pre_step: EventBinding[Event]
action: EventBinding[Event]
phase_end: EventBinding[PhaseEndEvent]
step_metrics: EventBinding[StepMetricsEvent]
def __init__(self):
self.phase_start = EventBinding[Event]('phase-start')
self.pre_step = EventBinding[Event]('pre-step')
self.action = EventBinding[Event]('action')
self.phase_end = EventBinding[PhaseEndEvent]('phase-end')
self.step_metrics = EventBinding[StepMetricsEvent]('step-metrics')
from typing import Iterable, Iterator
from torch.utils.data import DataLoader
import torch.optim as optim
from mini.temporal.dopesheet import Dopesheet
from mini.temporal.timeline import Timeline
from utils.progress import co_op, Progress
def reiterate[T](it: Iterable[T]) -> Iterator[T]:
"""
Iterates over an iterable indefinitely.
When the iterable is exhausted, it starts over from the beginning. Unlike
`itertools.cycle`, yielded values are not cached — so each iteration may be
different.
"""
while True:
yield from it
async def train_color_model( # noqa: C901
model: ColorMLP,
datasets: dict[str, tuple[DataLoader, Tensor]],
dopesheet: Dopesheet,
loss_criteria: dict[str, LossCriterion | SpecialLossCriterion],
event_handlers: EventHandlers | None = None,
):
if event_handlers is None:
event_handlers = EventHandlers()
# --- Validate inputs ---
# Check if all phases in dopesheet have corresponding data
dopesheet_phases = dopesheet.phases
missing_data = dopesheet_phases - set(datasets.keys())
if missing_data:
raise ValueError(f'Missing data for dopesheet phases: {missing_data}')
# Check if 'lr' is defined in the dopesheet properties
if 'lr' not in dopesheet.props:
raise ValueError("Dopesheet must define the 'lr' property column.")
# --- End Validation ---
timeline = Timeline(dopesheet)
optimizer = optim.Adam(model.parameters(), lr=0)
device = next(model.parameters()).device
data_iterators = {
phase_name: iter(reiterate(dataloader)) #
for phase_name, (dataloader, _) in datasets.items()
}
total_steps = len(timeline)
async with Progress(total=total_steps, description='Training Steps') as pbar:
async for step in co_op(pbar):
# Get state *before* advancing timeline for this step's processing
current_state = timeline.state
current_phase_name = current_state.phase
# Assuming TensorDataset yields a tuple with one element
(batch,) = next(data_iterators[current_phase_name])
# --- Event Handling ---
event_template = {
'step': step,
'model': model,
'timeline_state': current_state,
'optimizer': optimizer,
}
if current_state.is_phase_start:
event = Event(name=f'phase-start:{current_phase_name}', **event_template)
event_handlers.phase_start.emit(event.name, event)
event_handlers.phase_start.emit('phase-start', event)
for action in current_state.actions:
event = Event(name=f'action:{action}', **event_template)
event_handlers.action.emit(event.name, event)
event_handlers.action.emit('action', event)
event = Event(name='pre-step', **event_template)
event_handlers.pre_step.emit('pre-step', event)
# --- Training Step ---
# ... (get data, update LR, zero grad, forward pass, calculate loss, backward, step) ...
current_lr = current_state.props['lr']
for param_group in optimizer.param_groups:
param_group['lr'] = current_lr
optimizer.zero_grad()
outputs, latents = model(batch.to(device))
current_results = InferenceResult(outputs, latents)
total_loss = torch.tensor(0.0, device=device)
losses_dict: dict[str, float] = {}
for name, criterion in loss_criteria.items():
weight = current_state.props.get(name, 0.0)
if weight == 0:
continue
if isinstance(criterion, SpecialLossCriterion):
# Special criteria might run on their own data (like Anchor)
# or potentially use the current batch (depends on implementation).
# The forward method gets the model and the *current batch*
special_results = criterion.forward(model, batch)
if special_results is None:
continue
term_loss = criterion(batch, special_results)
else:
term_loss = criterion(batch, current_results)
total_loss += term_loss * weight
losses_dict[name] = term_loss.item()
if total_loss > 0:
total_loss.backward()
optimizer.step()
# --- End Training Step ---
# Emit step metrics event
step_metrics_event = StepMetricsEvent(
name='step-metrics',
**event_template,
total_loss=total_loss.item(),
losses=losses_dict,
)
event_handlers.step_metrics.emit('step-metrics', step_metrics_event)
# --- Post-Step Event Handling ---
if current_state.is_phase_end:
# Trigger phase-end for the *current* phase
_, validation_data = datasets[current_phase_name]
with torch.no_grad():
val_outputs, val_latents = model(validation_data.to(device))
event = PhaseEndEvent(
name=f'phase-end:{current_phase_name}',
**event_template,
validation_data=validation_data,
inference_result=InferenceResult(val_outputs, val_latents),
)
event_handlers.phase_end.emit(event.name, event)
event_handlers.phase_end.emit('phase-end', event)
# --- End Event Handling ---
# Update progress bar
pbar.metrics = {
'PHASE': current_phase_name,
'lr': f'{current_lr:.6f}',
'loss': f'{total_loss.item():.4f}',
**{name: f'{lt:.4f}' for name, lt in losses_dict.items()},
}
# Advance timeline *after* processing the current step
if step < total_steps: # Avoid stepping past the end
timeline.step()
log.info('Training finished!')
Phase plotting callback
This PhasePlotter class acts as an event handler. It listens for phase-end events emitted by the training loop. When a phase ends, it captures the model's latent representations for the validation data of that phase and generates plots showing the state of the latent space (projected onto different 2D planes). This allows us to visualize how the structure evolves across the curriculum.
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
from torch import Tensor
from IPython.display import HTML
from utils.nb import save_fig
class PhasePlotter:
"""Event handler to plot latent space at the end of each phase."""
def __init__(self, dim_pairs: list[tuple[int, int]] | None = None):
from utils.nb import displayer
# Store (phase_name, end_step, data, result) - data comes from event now
self.history: list[tuple[str, int, Tensor, InferenceResult]] = []
self.display = displayer()
self.dim_pairs = dim_pairs or [(0, 1), (0, 2)]
# Expect PhaseEndEvent specifically
def __call__(self, event: PhaseEndEvent):
"""Handle phase-end events."""
if not isinstance(event, PhaseEndEvent):
raise TypeError(f'Expected PhaseEndEvent, got {type(event)}')
# TODO: Don't assume device = CPU
# TODO: Split this class so that the event handler is separate from the plotting, and so the plotting can happen locally with @run.hither
phase_name = event.timeline_state.phase
end_step = event.step
phase_dataset = event.validation_data
inference_result = event.inference_result
log.info(f'Plotting end of phase: {phase_name} at step {end_step} using provided results.')
# Append to history
self.history.append((phase_name, end_step, phase_dataset.cpu(), inference_result.cpu()))
# Plotting logic remains the same as it already expected CPU tensors
fig = self._plot_phase_history()
self.display(
HTML(
save_fig(
fig,
'large-assets/ex-1.5-color-phase-history.png',
alt_text='Visualizations of latent space at the end of each curriculum phase.',
)
)
)
def _plot_phase_history(self):
num_phases = len(self.history)
plt.style.use('dark_background')
if num_phases == 0:
fig, ax = plt.subplots()
fig.set_facecolor('#333')
ax.set_facecolor('#222')
ax.text(0.5, 0.5, 'Waiting...', ha='center', va='center')
return fig
fig, axes = plt.subplots(
num_phases, len(self.dim_pairs), figsize=(5 * len(self.dim_pairs), 5 * num_phases), squeeze=False
)
fig.set_facecolor('#333')
for row_idx, (phase_name, end_step, data, res) in enumerate(self.history):
_latents = res.latents.numpy()
_colors = data.numpy()
for col_idx, (dim1, dim2) in enumerate(self.dim_pairs):
ax = axes[row_idx, col_idx]
ax.set_facecolor('#222')
ax.scatter(_latents[:, dim1], _latents[:, dim2], c=_colors, s=50, alpha=0.7)
# Set y-label differently for the first column
if col_idx == 0:
ax.set_ylabel(
f'Phase: {phase_name}\n(End Step: {end_step})',
fontsize='medium',
rotation=90, # Rotate vertically
labelpad=15, # Adjust padding
verticalalignment='center',
horizontalalignment='center',
)
else:
# Standard y-label for other columns
ax.set_ylabel(f'Dim {dim2}')
# Set title only for the top row
if row_idx == 0:
ax.set_title(f'Dims {dim1} vs {dim2}')
# Standard x-label for all columns
ax.set_xlabel(f'Dim {dim1}')
# Keep other plot settings
ax.axhline(y=0, color='gray', linestyle='--', alpha=0.5)
ax.axvline(x=0, color='gray', linestyle='--', alpha=0.5)
ax.add_patch(Circle((0, 0), 1, fill=False, linestyle='--', color='gray', alpha=0.3))
ax.set_aspect('equal')
fig.tight_layout()
return fig
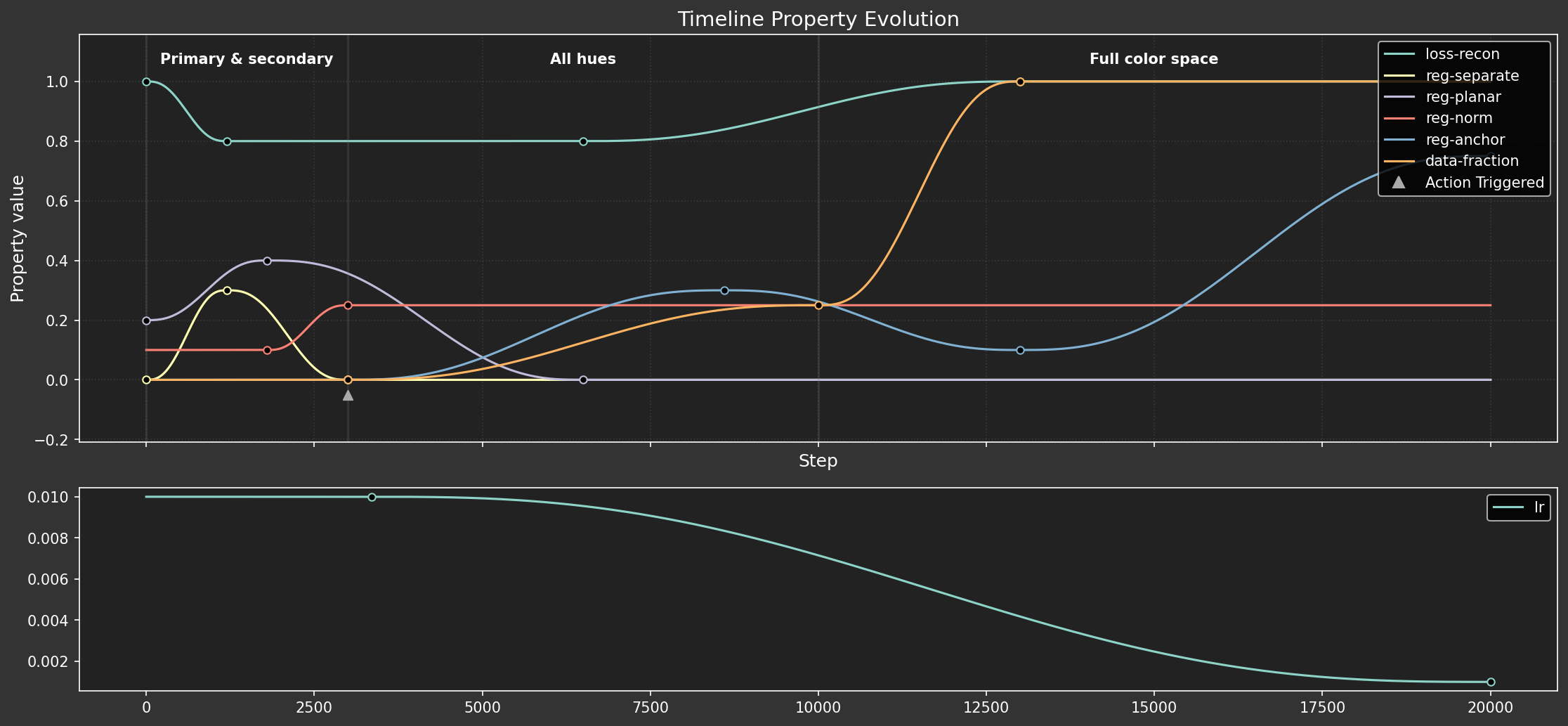
Smooth curriculum via dopesheet
Instead of defining discrete phases with fixed parameters, we now use a dopesheet (as CSV) to define keyframes for our hyperparameters. The Timeline class interpolates these values smoothly between keyframes using the minimum jerk approach from Experiment 1.4.
The dopesheet controls:
- Learning Rate (
lr): Gradually decreased over training. - Reconstruction Loss Weight (
loss-recon): Kept constant. - Regularization Weights (
reg-separate,reg-planar,reg-norm,reg-anchor): Faded in and out to guide the model. For example,reg-separateandreg-planarare strong early on to establish the color wheel, whilereg-anchoractivates later to lock it in place. - Data Fraction (
data-fraction): Controls theDynamicWeightedRandomBatchSamplerto smoothly transition the training data distribution from vibrant colors towards the full color space (details below). - Actions (
ACTION): Triggers specific events, like theanchoraction which tells theAnchorregularizer to capture the current latent positions of the primary/secondary colors.
This allows for a more continuous and potentially more stable learning process.
from IPython.display import display, HTML, Markdown
from matplotlib import pyplot as plt
from matplotlib.figure import Figure
from mini.temporal.vis import group_properties_by_scale, plot_timeline, realize_timeline
from mini.temporal.dopesheet import Dopesheet
from mini.temporal.timeline import Timeline
from utils.nb import save_fig
dopesheet = Dopesheet.from_csv('ex-1.5-dopesheet.csv')
display(
Markdown(f"""
## Parameter schedule
{dopesheet.to_markdown()}
""")
)
timeline = Timeline(dopesheet)
history_df = realize_timeline(timeline)
keyframes_df = dopesheet.as_df()
groups = group_properties_by_scale(keyframes_df[dopesheet.props])
fig, ax = plot_timeline(history_df, keyframes_df, groups)
# Add assertion to satisfy type checker
assert isinstance(fig, Figure), 'plot_timeline should return a Figure'
display(
HTML(
save_fig(
fig, # Now type checker is happy
'large-assets/ex-1.5-color-timeline.png',
alt_text='Line chart showing the hyperparameter schedule over time.',
)
)
)
I 386.3 ut.nb: Figure saved: 'large-assets/ex-1.5-color-timeline.png'
Loss functions and regularizers
We use mean squared error for the main reconstruction loss (loss-recon). The following regularizers, weighted according to the dopesheet schedule, guide the latent space structure:
unitarity(reg-norm): Encourages latent vectors to lie on a unit hypersphere by penalizing deviations from a norm of 1.planarity(reg-planar): Pushes dimensions beyond the first two towards zero, encouraging the primary hue structure to form in the first two dimensions.Separate(reg-separate): Pushes latent points away from each other, primarily used in the early phase to spread out the primary/secondary colors.Anchor(reg-anchor): This is aSpecialLossCriterion. When theanchoraction is triggered by the timeline, itson_anchormethod captures the current latent positions of a reference dataset (the primary/secondary colors). Subsequently, its__call__method calculates a loss based on how far the current model places those reference colors from their captured anchor positions. This penalizes drift in the established structure.
from torch import linalg as LA
from ex_color.data.color_cube import ColorCube
from ex_color.data.cyclic import arange_cyclic
def objective(fn):
"""Adapt loss function to look like a regularizer"""
def wrapper(data: Tensor, res: InferenceResult) -> Tensor:
return fn(data, res.outputs)
return wrapper
def unitarity(data: Tensor, res: InferenceResult) -> Tensor:
"""Regularize latents to have unit norm (vectors of length 1)"""
norms = LA.vector_norm(res.latents, dim=-1)
return torch.mean((norms - 1.0) ** 2)
def planarity(data: Tensor, res: InferenceResult) -> Tensor:
"""Regularize latents to be planar in the first two channels (so zero in other channels)"""
return torch.mean(res.latents[:, 2:] ** 2)
class Separate(LossCriterion):
def __init__(self, channels: tuple[int, ...] = (0, 1)):
self.channels = channels
def __call__(self, data: Tensor, res: InferenceResult) -> Tensor:
"""Regularize latents to be separated from each other in first two channels"""
# Get pairwise differences in the first two dimensions
points = res.latents[:, self.channels] # [B, C]
diffs = points.unsqueeze(1) - points.unsqueeze(0) # [B, B, C]
# Calculate squared distances
sq_dists = torch.sum(diffs**2, dim=-1) # [B, B]
# Remove self-distances (diagonal)
mask = 1.0 - torch.eye(sq_dists.shape[0], device=sq_dists.device)
masked_sq_dists = sq_dists * mask
# Encourage separation by minimizing inverse distances (stronger repulsion between close points)
epsilon = 1e-6 # Prevent division by zero
return torch.mean(1.0 / (masked_sq_dists + epsilon))
class Anchor(SpecialLossCriterion):
"""Regularize latents to be close to their position in the reference phase"""
ref_data: Tensor
_ref_latents: Tensor | None = None
def __init__(self, ref_data: Tensor):
self.ref_data = ref_data
self._ref_latents = None
log.info(f'Anchor initialized with reference data shape: {ref_data.shape}')
def forward(self, model: ColorMLP, data: Tensor) -> InferenceResult | None:
"""Run the *stored reference data* through the *current* model."""
# Note: The 'data' argument passed by the training loop for SpecialLossCriterion
# is the *current training batch*, which we IGNORE here.
# We only care about running our stored _ref_data through the model.
device = next(model.parameters()).device
ref_data = self.ref_data.to(device)
outputs, latents = model(ref_data)
return InferenceResult(outputs, latents)
def __call__(self, data: Tensor, special: InferenceResult) -> Tensor:
"""Calculates loss between current model's latents (for ref_data) and the stored reference latents."""
if self._ref_latents is None:
# This means on_anchor hasn't been called yet, so the anchor loss is zero.
# This prevents errors during the very first phase before the anchor point is set.
log.debug('Anchor.__call__ invoked before reference latents captured. Returning zero loss.')
return torch.tensor(0.0, device=special.latents.device)
ref_latents = self._ref_latents.to(special.latents.device)
return torch.mean((special.latents - ref_latents) ** 2)
def on_anchor(self, event: Event):
# Called when the 'anchor' event is triggered
log.info(f'Capturing anchor latents via Anchor.on_anchor at step {event.step}')
device = next(event.model.parameters()).device
ref_data = self.ref_data.to(device)
with torch.no_grad():
_, latents = event.model(ref_data)
self._ref_latents = latents.detach().cpu()
log.info(f'Anchor state captured internally. Ref data: {ref_data.shape}, Ref latents: {latents.shape}')
Data loading, sampling, and event handling
Here we set up:
- Datasets: Define the datasets used (primary/secondary colors, full color grid).
- Sampler: Use
DynamicWeightedRandomBatchSamplerfor the full dataset. Its weights are updated by theupdate_sampler_weightscallback, which responds to thedata-fractionparameter from the dopesheet. This smoothly shifts the sampling focus from highly vibrant colors early on to the full range of colors later. - Recorders:
ModelRecorderandMetricsRecorderare event handlers that save the model state and loss values at each step. - Event bindings: Connect event handlers to specific events (e.g.,
plottertophase-end,reg_anchor.on_anchortoaction:anchor, recorders topre-stepandstep-metrics). - Training execution: Finally, call
train_color_modelwith the model, datasets, dopesheet, loss criteria, and configured event handlers.
import numpy as np
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from ex_color.data.cube_sampler import DynamicWeightedRandomBatchSampler, vibrancy
from ex_color.data.filters import levels
class ModelRecorder(EventHandler):
"""Event handler to record model parameters."""
history: list[tuple[int, dict[str, Tensor]]]
"""A list of tuples (step, state_dict) where state_dict is a copy of the model's state dict."""
def __init__(self):
self.history = []
def __call__(self, event: Event):
# It's crucial to get a *copy* of the state dict and move it to the CPU
# so we don't hold onto GPU memory or track gradients unnecessarily.
model_state = {k: v.cpu().clone() for k, v in event.model.state_dict().items()}
self.history.append((event.step, model_state))
log.debug(f'Recorded model state at step {event.step}')
class MetricsRecorder(EventHandler):
"""Event handler to record training metrics."""
history: list[tuple[int, float, dict[str, float]]]
"""A list of tuples (step, total_loss, losses_dict)."""
def __init__(self):
self.history = []
def __call__(self, event: StepMetricsEvent):
# Ensure we are handling the correct event type
if not isinstance(event, StepMetricsEvent):
log.warning(f'MetricsRecorder received unexpected event type: {type(event)}')
return
self.history.append((event.step, event.total_loss, event.losses.copy()))
log.debug(f'Recorded metrics at step {event.step}: loss={event.total_loss:.4f}')
primary_cube = ColorCube.from_hsv(h=arange_cyclic(step_size=1 / 6), s=np.ones(1), v=np.ones(1))
primary_tensor = torch.tensor(primary_cube.rgb_grid.reshape(-1, 3), dtype=torch.float32)
primary_dataset = TensorDataset(primary_tensor)
primary_loader = DataLoader(primary_dataset, batch_size=len(primary_tensor))
full_cube = ColorCube.from_hsv(
h=arange_cyclic(step_size=10 / 360),
s=np.linspace(0, 1, 10),
v=np.linspace(0, 1, 10),
)
full_tensor = torch.tensor(full_cube.rgb_grid.reshape(-1, 3), dtype=torch.float32)
full_dataset = TensorDataset(full_tensor)
full_sampler = DynamicWeightedRandomBatchSampler(
bias=full_cube.bias.flatten(),
batch_size=256,
steps_per_epoch=100,
)
vibrancy_weights = vibrancy(full_cube).flatten()
full_loader = DataLoader(full_dataset, batch_sampler=full_sampler)
rgb_cube = ColorCube.from_rgb(
r=np.linspace(0, 1, 10),
g=np.linspace(0, 1, 10),
b=np.linspace(0, 1, 10),
)
rgb_tensor = torch.tensor(rgb_cube.rgb_grid.reshape(-1, 3), dtype=torch.float32)
def update_sampler_weights(event: Event):
frac = event.timeline_state.props['data-fraction']
# When the fraction is near zero, in_low is almost 1 — which means "scale everything down to 0 except for 1"
# When the fraction is 0.5, in_low and out_low are both 0, so the weights are unchanged
# When the fraction is 1, in_low is 0 and out_low is 1, so the weights are all scaled to 1
in_low = np.interp(frac, [0, 0.5], [0.99, 0])
out_low = np.interp(frac, [0.5, 1], [0, 1])
full_sampler.weights = levels(vibrancy_weights, in_low=in_low, out_low=out_low)
recorder = ModelRecorder()
metrics_recorder = MetricsRecorder()
# Phase -> (train loader, validation tensor)
datasets: dict[str, tuple[DataLoader, Tensor]] = {
'Primary & secondary': (primary_loader, primary_tensor),
'All hues': (full_loader, rgb_tensor),
'Full color space': (full_loader, rgb_tensor),
}
model = ColorMLP(normalize_bottleneck=False)
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
log.info(f'Model initialized with {total_params:,} trainable parameters.')
event_handlers = EventHandlers()
event_handlers.pre_step.add_handler('pre-step', recorder)
event_handlers.pre_step.add_handler('pre-step', update_sampler_weights)
event_handlers.step_metrics.add_handler('step-metrics', metrics_recorder)
plotter = PhasePlotter(dim_pairs=[(0, 1), (0, 2), (0, 3)])
event_handlers.phase_end.add_handler('phase-end', plotter)
reg_anchor = Anchor(ref_data=primary_tensor)
event_handlers.action.add_handler('action:anchor', reg_anchor.on_anchor)
history = await train_color_model(
model,
datasets,
dopesheet,
loss_criteria={
'loss-recon': objective(nn.MSELoss()),
'reg-separate': Separate((0, 1)),
'reg-planar': planarity,
'reg-norm': unitarity,
'reg-anchor': reg_anchor,
},
event_handlers=event_handlers,
)
I 420.9 no: Model initialized with 263 trainable parameters.
I 420.9 no: Anchor initialized with reference data shape: torch.Size([6, 3])
I 425.3 no: Plotting end of phase: Primary & secondary at step 2999 using provided results. I 425.8 ut.nb: Figure saved: 'large-assets/ex-1.5-color-phase-history.png' I 425.8 ut.nb: Figure saved: 'large-assets/ex-1.5-color-phase-history.png'
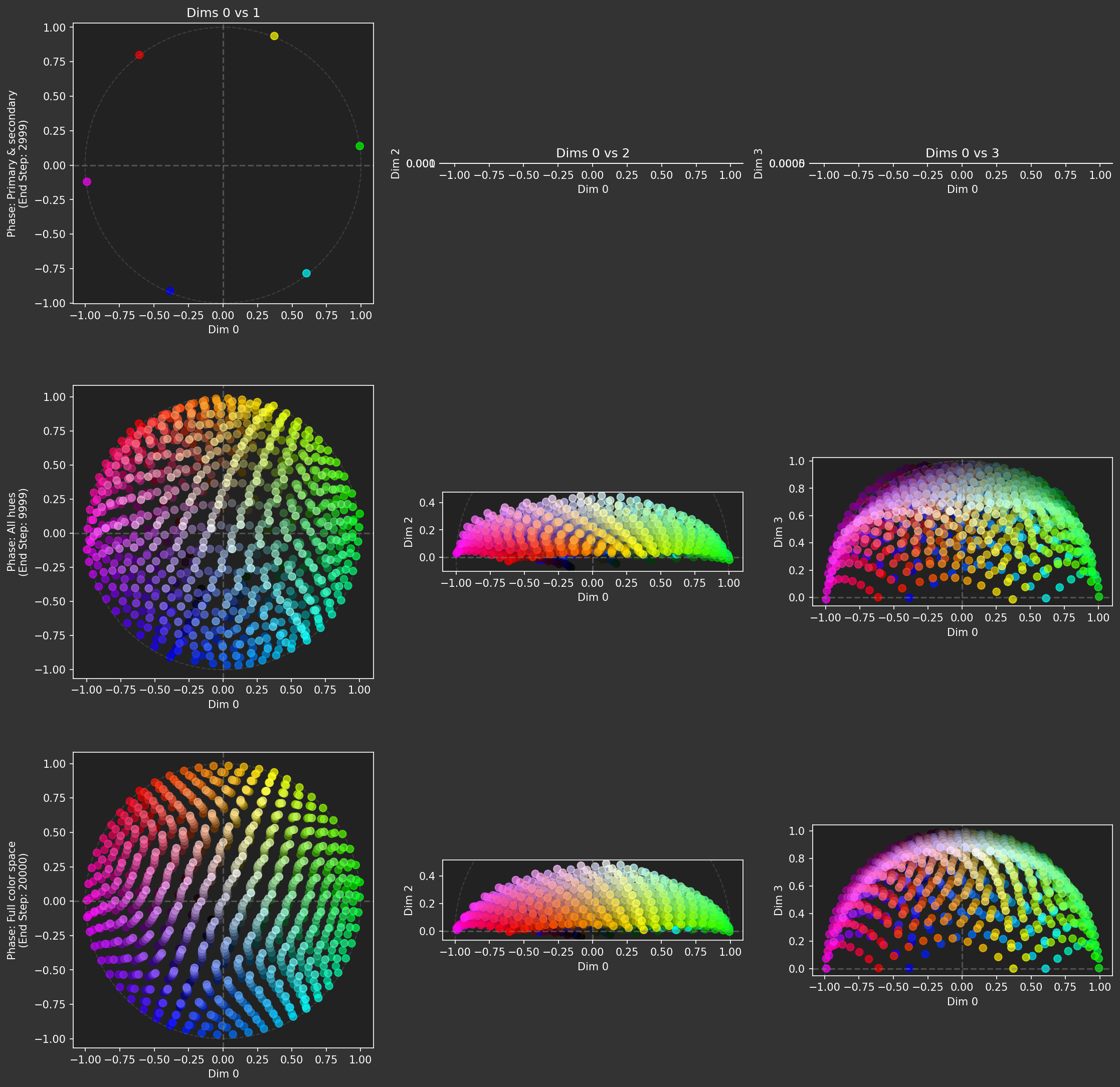
I 425.8 no: Capturing anchor latents via Anchor.on_anchor at step 3000 I 425.8 no: Anchor state captured internally. Ref data: torch.Size([6, 3]), Ref latents: torch.Size([6, 4]) I 425.8 no: Anchor state captured internally. Ref data: torch.Size([6, 3]), Ref latents: torch.Size([6, 4]) I 444.1 no: Plotting end of phase: All hues at step 9999 using provided results. I 444.1 no: Plotting end of phase: All hues at step 9999 using provided results. I 444.5 ut.nb: Figure saved: 'large-assets/ex-1.5-color-phase-history.png' I 444.5 ut.nb: Figure saved: 'large-assets/ex-1.5-color-phase-history.png' I 469.6 no: Plotting end of phase: Full color space at step 20000 using provided results. I 469.6 no: Plotting end of phase: Full color space at step 20000 using provided results. I 470.3 ut.nb: Figure saved: 'large-assets/ex-1.5-color-phase-history.png' I 470.3 no: Training finished! I 470.3 ut.nb: Figure saved: 'large-assets/ex-1.5-color-phase-history.png' I 470.3 no: Training finished!
Latent space evolution analysis
Let's visualize how the latent space evolved over time. We use the ModelRecorder's history to load the model state at each recorded step and evaluate the latent positions for a fixed set of input colors (the full RGB grid). This gives us a sequence of latent space snapshots.
import numpy as np
async def eval_latent_history(
recorder: ModelRecorder,
rgb_tensor: Tensor,
):
"""Evaluate the latent space for each step in the recorder's history."""
# Create a new model instance
from utils.progress import Progress
model = ColorMLP(normalize_bottleneck=False)
latent_history: list[tuple[int, np.ndarray]] = []
# Iterate over the recorded history
async for step, state_dict in co_op(Progress(recorder.history, description='Evaluating latents')):
# Load the model state dict
model.load_state_dict(state_dict)
model.eval()
with torch.no_grad():
# Get the latents for the RGB tensor
_, latents = model(rgb_tensor.to(next(model.parameters()).device))
latents = latents.cpu().numpy()
latent_history.append((step, latents))
return latent_history
latent_history = await eval_latent_history(recorder, rgb_tensor)
Animation of latent space
This final visualization combines multiple views into a single animation:
- Latent space: Shows the 2D projection (Dims 0 vs 1) of the latent embeddings for the full RGB color grid, colored by their true RGB values. We can see the color wheel forming and potentially expanding/contracting.
- Hyperparameters: Replots the parameter schedule from the dopesheet, with a vertical line indicating the current step in the animation.
- Training metrics: Plots the total loss and the contribution of each individual loss/regularization term (on a log scale), again with a vertical line for the current step.
(Note: A variable stride is used for sampling frames to focus on periods of rapid change.)
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import imageio_ffmpeg
from matplotlib import rcParams
import pandas as pd
from mini.temporal.dopesheet import RESERVED_COLS
from utils.progress import Progress
from mini.temporal.vis import group_properties_by_scale, plot_timeline
from utils.progress.progress import SyncProgress
rcParams['animation.ffmpeg_path'] = imageio_ffmpeg.get_ffmpeg_exe()
def animate_latent_evolution_with_metrics(
latent_history: list[tuple[int, np.ndarray]],
metrics_history: list[tuple[int, float, dict[str, float]]],
param_history_df: pd.DataFrame,
param_keyframes_df: pd.DataFrame,
colors: np.ndarray,
dim_pair: tuple[int, int] = (0, 1),
interval=1 / 30,
):
"""Create an animation of the latent space evolution alongside hyperparameter and metric plots."""
plt.style.use('dark_background')
# Create a figure with 3 subplots: 1 for latent, 2 for lines
fig = plt.figure(figsize=(12, 6))
gs = fig.add_gridspec(2, 2, width_ratios=[1, 1], height_ratios=[1, 1])
ax_latent = fig.add_subplot(gs[:, 0]) # Latent space on the left, spanning rows
ax_params = fig.add_subplot(gs[0, 1]) # Params top right
ax_metrics = fig.add_subplot(gs[1, 1]) # Metrics bottom right
fig.patch.set_facecolor('#333')
ax_latent.patch.set_facecolor('#222')
ax_params.patch.set_facecolor('#222')
ax_metrics.patch.set_facecolor('#222')
# --- Setup Latent Plot ---
ax_latent.set_xlim(-1.5, 1.5)
ax_latent.set_ylim(-1.5, 1.5)
ax_latent.set_aspect('equal')
ax_latent.set_xlabel(f'Dim {dim_pair[0]}')
ax_latent.set_ylabel(f'Dim {dim_pair[1]}')
step, current_latents = latent_history[0]
scatter = ax_latent.scatter(
current_latents[:, dim_pair[0]], current_latents[:, dim_pair[1]], c=colors, s=30, alpha=0.7
)
title_latent = ax_latent.set_title(f'Latent Space (Step {step})')
# --- Setup Parameter Plot ---
# Filter out 'STEP' and other reserved columns before grouping
param_props = param_keyframes_df.columns.difference(list(RESERVED_COLS)).tolist()
param_groups = group_properties_by_scale(param_keyframes_df[param_props])
# Pass only the first group if plotting on a specific axis
plot_timeline(param_history_df, param_keyframes_df, [param_groups[0]], ax=ax_params, show_legend=True)
param_vline = ax_params.axvline(step, color='white', linestyle='--', lw=1)
ax_params.set_title('Hyperparameters')
ax_params.set_xlabel('') # Remove x-label as it shares with metrics
ax_params.tick_params(axis='x', labelbottom=False)
# --- Setup Metrics Plot ---
metrics_steps = [h[0] for h in metrics_history]
total_losses = [h[1] for h in metrics_history]
loss_components = {k: [h[2].get(k, np.nan) for h in metrics_history] for k in metrics_history[0][2].keys()}
ax_metrics.plot(metrics_steps, total_losses, label='Total Loss', lw=2)
for name, values in loss_components.items():
ax_metrics.plot(metrics_steps, values, label=name, lw=1, alpha=0.8)
ax_metrics.set_xlabel('Step')
ax_metrics.set_ylabel('Loss (log scale)') # Update label
ax_metrics.set_title('Training Metrics')
ax_metrics.legend(fontsize='small')
ax_metrics.set_yscale('log') # Set log scale
ax_metrics.set_ylim(bottom=1e-6) # Set bottom slightly above zero for log scale
metrics_vline = ax_metrics.axvline(step, color='white', linestyle='--', lw=1)
# Use uppercase 'STEP' for accessing the history_df column
max_step = param_history_df['STEP'].max()
ax_metrics.set_xlim(left=0, right=max_step)
ax_params.set_xlim(left=0, right=max_step)
fig.tight_layout()
def update(frame: int):
# frame is the index in the *sampled* history
latent_step, current_latents = latent_history[frame]
# Update latent space
scatter.set_offsets(current_latents[:, dim_pair])
title_latent.set_text(f'Latent Space (Step {latent_step})')
# Update vertical lines
param_vline.set_xdata([latent_step])
metrics_vline.set_xdata([latent_step])
return scatter, title_latent, param_vline, metrics_vline
# Use the length of the (potentially strided) latent_history for frames
num_frames = len(latent_history)
ani = animation.FuncAnimation(fig, update, frames=num_frames, interval=interval * 1000, blit=True)
return fig, ani
# --- Variable Stride Logic ---
def get_stride(step: int):
import math
a = 7.9236
b = 0.0005
return a * math.log(b * step + 1) + 1
sampled_indices = [0]
last_sampled_index = 0
while True:
# Get the step number corresponding to the last sampled frame
current_step = latent_history[round(last_sampled_index)][0]
# Determine the stride based on that step number
stride = get_stride(current_step)
# Calculate the index of the next potential frame
next_index = last_sampled_index + stride
# Stop if we've gone past the end of the history
if round(next_index) >= len(latent_history):
break
# Add the calculated index to our list
sampled_indices.append(round(next_index))
# Update the last sampled index for the next iteration
last_sampled_index = next_index
# Use the sampled indices to select frames from the full history
sampled_latent_history = [latent_history[i] for i in sampled_indices]
# --- End Variable Stride Logic ---
# Filter metrics history to align with the *new* sampled latent history steps
sampled_steps_set = {step for step, _ in sampled_latent_history}
filtered_metrics_history = [h for h in metrics_recorder.history if h[0] in sampled_steps_set]
# Make sure we have the parameter history dataframes (they were created earlier)
# history_df, keyframes_df
fig, ani = animate_latent_evolution_with_metrics(
latent_history=sampled_latent_history, # Use variable stride history
metrics_history=filtered_metrics_history, # Use filtered metrics
param_history_df=history_df, # Full parameter history
param_keyframes_df=keyframes_df, # Keyframes for plotting
colors=rgb_tensor.cpu().numpy(),
dim_pair=(0, 1),
)
video_file = 'large-assets/ex-1.5-latent-evolution-with-metrics.mp4' # New filename
num_frames_to_render = len(sampled_latent_history) # Update frame count
with SyncProgress(total=num_frames_to_render, description='Rendering video') as pbar:
ani.save(
video_file,
fps=30,
extra_args=['-vcodec', 'libx264'],
progress_callback=lambda i, n: pbar.update(total=n, count=i),
)
plt.close(fig)
from random import randint
from IPython.display import display, HTML
cache_buster = randint(1, 1_000_000)
display(
HTML(
f"""
<video width="960" height="480" controls loop>
<source src="{video_file}?v={cache_buster:d}" type="video/mp4">
Your browser does not support the video tag.
</video>
"""
)
)